
With so many different forms of data collection on conflict and violence types and locations, it is often difficult to know how these various data compare and to what extent they describe and record the same events.
On one end of the spectrum lie data initiatives that rely on crowdsourcing, in which individuals at the local-level recount firsthand information through reporting conflict that they witness. This is done through formats such as text messaging or tweets; these means of reporting are in turn able to provide the geographical location of the reporting individual, and hence the proposed conflict event. These types of data capitalize on the ability of numerous individuals to report on conflict and violence at once and in real-time – essentially providing countless conflict ‘reporters’ who relay information on conflict events as they happen.
Some disadvantages exist with this type of reporting including whether political violence outside of urban areas is accurately collected; political violence outside of ‘high interest’ periods is consistently recorded; and the verifiability of the information collected. The last is of critical importance: given the ability of everyone to contribute information via texts or tweets, there does not exist any type of verification to determine the accuracy of events (e.g., their existence, intensity, location, type, etc.). Additionally, in instances where such ‘reporters’ are to recount the violence type (i.e., riot, protest, clash, violence against civilians, etc.), different individuals may account for the same event differently. Hence, for example, even though in reality a single riot may have occurred, one person may ‘code’ this as a riot, while another as a protest, and even another as a clash. In that case, this may result in the illusion of more than one event happening at a specific time and place. Finally, in states with significant press freedom and multiple outlets for reporting, crowd-sourced or crowd-seeded data can produce little additional information.
On the other end of the spectrum lie data initiatives that make use of machines aggregating published reports on conflict and violence, and use information within these reports to determine conflict and violence types and locations. These types of data capitalize on the ability of machines to peruse numerous reports – including recently reported and posted ones – in a short period of time, resulting in near-up-to-date reporting. With this type of reporting, machines glean geographical, temporal, etc. information from reports in an effort to provide further information about conflict events.
However, despite the advantage of machines collecting a larger number of reports than human coders, machines have disadvantages relative to more curated forms of collection. Machine coding is often unable to attribute whether reports refer to the same conflict event. As a result, the same conflict event information published in multiple outlets can often be recorded as discrete events, creating the illusion of more than one event happening at a certain time and place.
Highly curated – and often manually coded data, such as ACLED information – falls somewhere in the middle of this spectrum. There are several areas where careful attention by researchers to information results in more valid, verifiable, thorough and ultimately more ‘usable’ conflict information. These include reporting depth, breadth, bias, and comprehensiveness.
While ACLED does not currently make use of individual-level reporting (e.g., texts and tweets) as crowdsourcing initiatives do, it does use reports from local news agencies to harness available information on violence to code conflict events, with hopes that further local-level sourcing will soon be more largely relied upon. ACLED draws from sources at the international, regional, national, local, and aggregate levels. This ensures that media biases related to reporting at a certain geographical level do not impact coding. From a review of these sources, some of the classic pitfalls of conflict coding – including urban biases, insufficient attention to non-fatal events, or an inability to capture conflict events as they occur in real-time and in localities – are countered through effective sourcing in ACLED (ACLED, 26 November 2014).
Relying on published reports instead of texts/tweets from individuals allows for a meticulous verification and triangulation process by each coder. Further, in order to ensure the most accurate data are cleaned and analysis-ready, ACLED implements a series of cleaning and checking. ACLED data go through checks of inter-coder, intra-coder, and inter-code reliability every week before the release of its weekly real-time conflict data. After a team of coders goes through the various media sources and systematically records conflict events that have occurred during the week, information goes through an extensive inter-code reliability test where codes are checked for correct numbering, event types, locations, etc. Next, all information is subjected to an intra-code reliability test where each submission by coders are compared to each other, and to original source materials to ensure accuracy. Coding is reviewed for inter-conflict reliability where notes relating to each conflict match the conflict event itself and whether the event should ultimately be included within the dataset (i.e., is the event an example of political violence). These various levels of cleaning and testing ensure that the weekly release of data continues at a high standard despite the quick turnaround time.
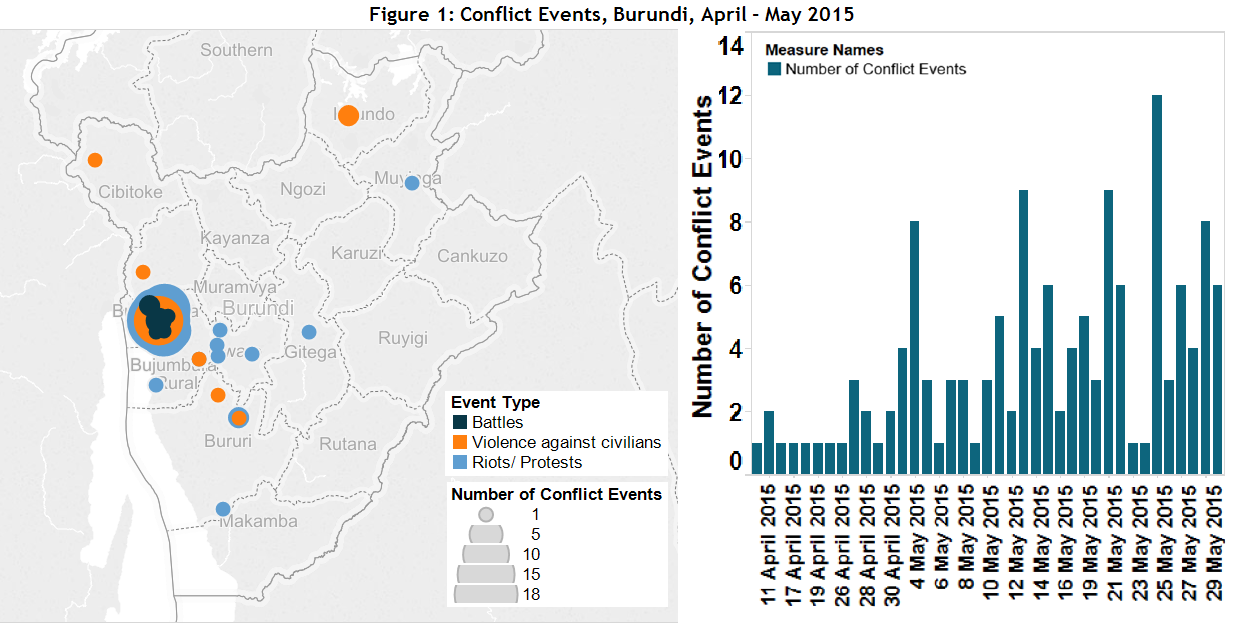
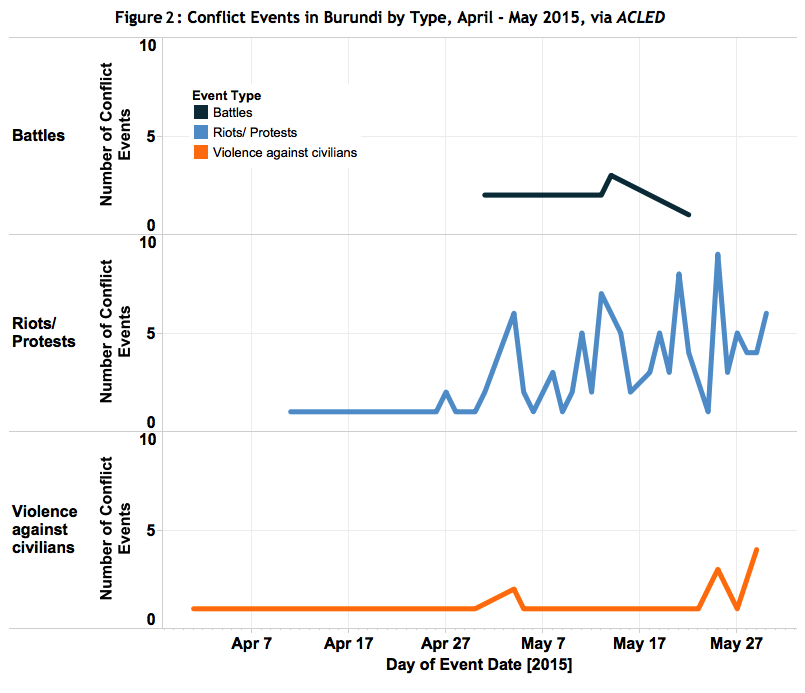
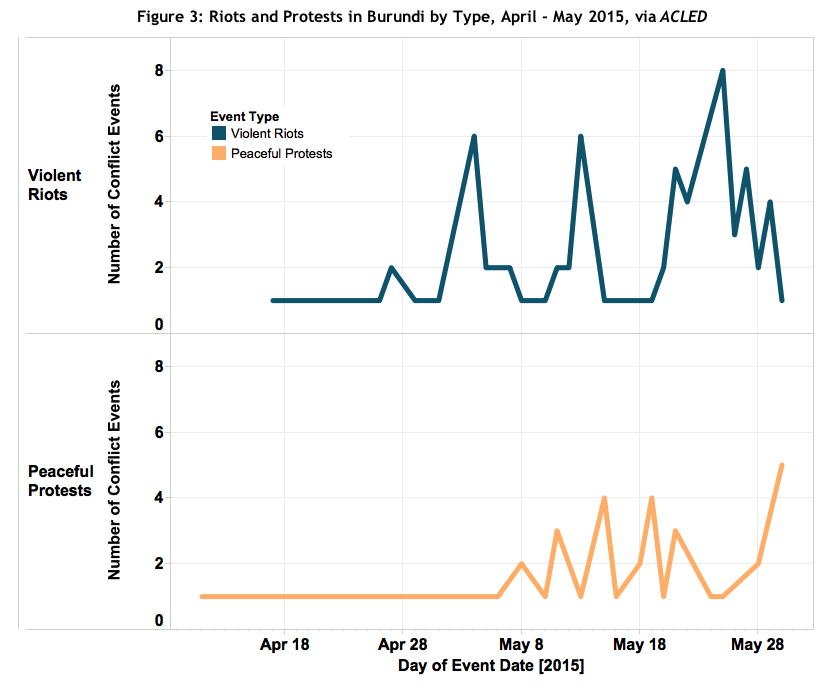
Using a coding system with numerous rounds of verification instead of crowdsourcing, like ACLED, can be seen in Figure 1 depicting political violence (both violence and riots and protests) since April 2015 based on ACLED data. While a crowdsourced map may show more nuanced data within the capital Bujumbura, ACLED data better account for increased instability in Burundi in recent weeks. Further, as ACLED data can be separated by conflict event type, it is possible to track what has been shaping changes in conflict dynamics in the country. Figure 2 depicts this disaggregation and shows that increases primarily in riots and protests, as well as civilian targeting, are what is driving this conflict trend in Burundi. Furthermore, as ACLED data provide information on who the conflict actors are specifically, it is able to further disaggregate these trends within riots and protests; Figure 3 depicts that while violent rioting peaked in late May, these types of actions are decreasing while more peaceful protests are increasing in number in Burundi. These further nuances in real-time conflict reporting are not available via other sources. Through an intensive process of engagement with local sources in Burundi, ACLED intends to harness the most thorough information on instability.
Manual coders are better able to make decisions regarding whether two reports refer to the same conflict event. ACLED is able to capitalize on the benefits of multiple source reporting on the same event by using triangulation techniques to ensure the most information about each conflict event is gleaned and coded (Weidmann and Rød, 2015). For example, fatality counts are an attribute of conflict that is open to much variation (for example, see Anyadike [2015] for a comparison of fatality counts related to Boko Haram’s conflict activity amongst ACLED, IRIN News, and Nigeria Watch). In an effort to not over-count fatalities, ACLED codes the most conservative reports of fatality counts, as reported in the most relevant and up-to-date reports. Overcounting deaths is an issue given the incentives to misrepresent death counts by the “systematic violence bias in mainstream news reports” (Day, Pinckney, and Chenoweth, 2015).
ACLED’s coders are also able to distinguish conflict parties more accurately – a problem for automated coders. Weller and McCubbins [2014], for example, describe how GDELT – a large-scale event and tone dataset relying on automated coding – misses one or both conflict actors in large proportions of its coding, as it can be difficult for a computer to determine these parties. Manual coders are able to account for subjective variation in reports, such as tone or biases, and ensure that only the relevant, objective information is coded.
For further reading on ACLED conflict reporting practices, and how they compare to other conflict coding methods and initiatives, see the ACLED Methodology page (ACLED, 2015).


