When working with quantitative data, it is often necessary to merge data from multiple datasets. For example, one might want to combine conflict data at the country-level from ACLED with data on health, climate change, gender, etc. from another source.[1] While the two datasets share a common identifying variable (e.g., country name), if these cells do not match perfectly – for example, “Côte d’Ivoire” in one dataset and “Ivory Coast” in another, or “Democratic Republic of the Congo” in one dataset and “DR-Congo” in another – software such as Microsoft Excel will not be able to identify that these varying country-names refer to one and the same.
While correcting this manually or by conducting a search-and-replace might be feasible in instances where only a few observations are mismatched, this issue can become much more difficult to grapple with in instances where mismatches are systemic. For example, if trying to match a span of 18 years with references to first-order administrative divisions across the entire continent of Africa – where a simple difference in the usage of accents across datasets (e.g., Médéa, Algeria versus Medea, Algeria), or references to English versus Arabic names of regions (e.g., North Sinai, Egypt versus Shamal Sina, Egypt) – it can quickly escalate into a task that is much too insurmountable manually. Add to this the fact that various countries may have administrative regions with the same name – for example, Gambia, Ghana, Kenya, Sierra Leone, and Zambia all have a first-order administrative region named ‘Western’ – it means that a simple search-and-replace is not a simple solution.
One way to confront this issue is through investing time in creating a ‘key’ – a one-time task – in which you pair (potential mis-)matches across your entire panel data. You can then pair these with a new identifying variable that you create; this new ID can serve as the ‘bridging link’ between your various datasets. Through the use of Excel formulas, it then becomes easy to assign this new ID to all of your observations, giving each observation a link to use in bridging across datasets. This new unique identifier can be helpful when using programs such as Stata to merge datasets.
See below for a visual walk-through of these steps:
Assume these data examples come from datasets on conflict and population that you are trying to combine[2]:
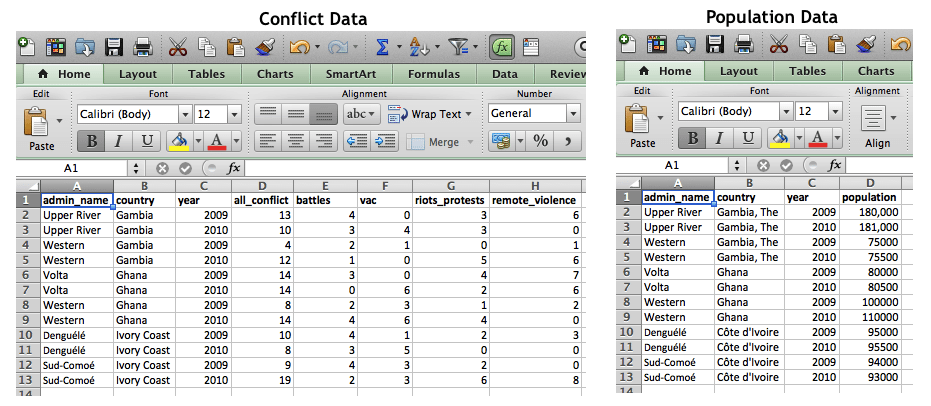
As you can see, while the same administrative regions, countries, and years are included in both datasets, they do not match exactly, and hence Excel is not able to identify them as matched terms.
First, it is best to create an admin-country variable; this will help decipher between matching admin names, such as Western, Gambia and Western, Ghana. This can be done by inserting a new column, and then creating a combined-variable using the formula:
=B2&C2
where B2 is the administrative region name and C2 is the country name, combined with an ampersand (&). This is then replicated for all observations in the dataset.
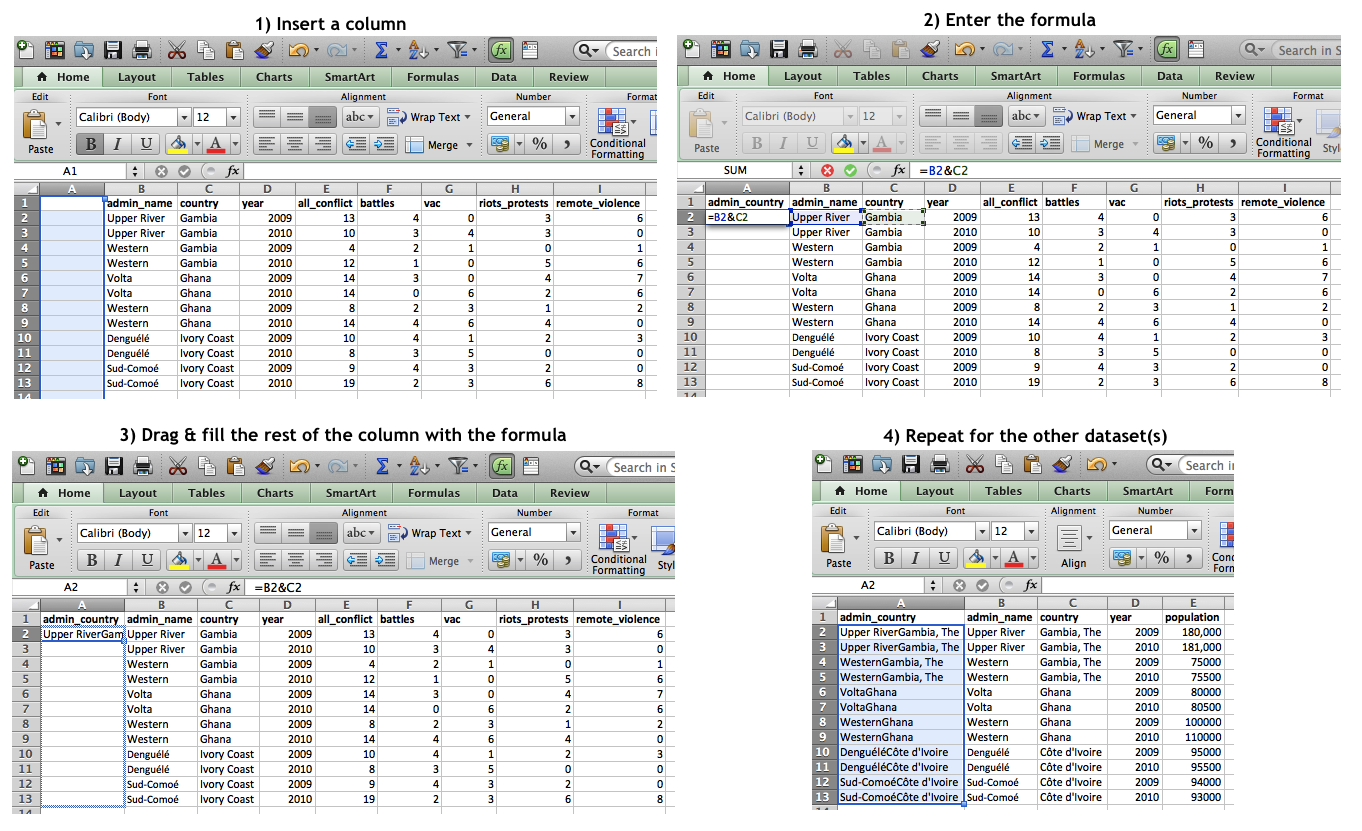
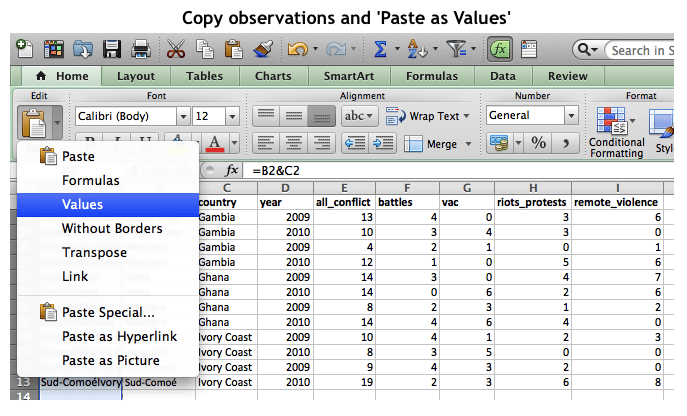
It is quite critical that after every step in which a formula is used, you make sure to copy and paste the newly generated entries as ‘values’ so that they will not be altered with the continued manipulation of the datasets.
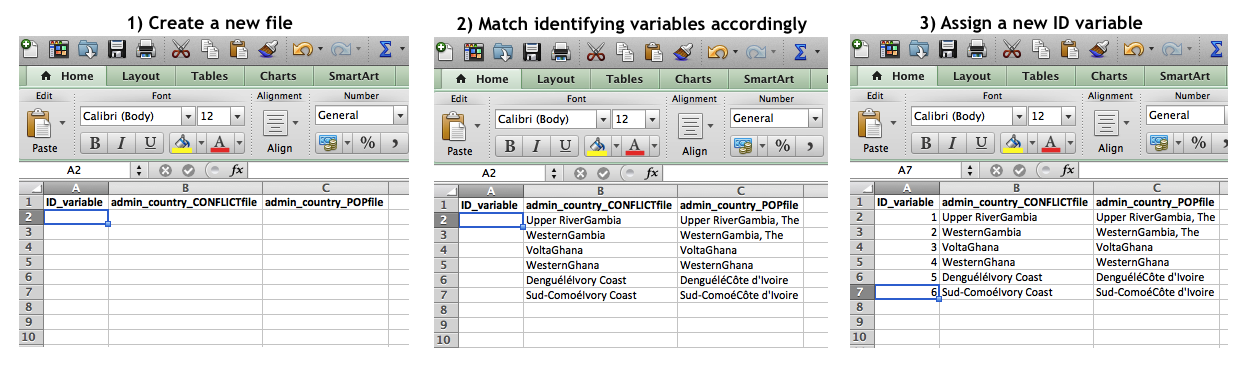
The next step is to create a new ‘key’ file in which the new admin-country variables from each dataset are matched to a newly created ID-variable. See Step 1 below. To do this, create a new file, with a column for your new ID variable, as well as a column for the identifier in each of your datasets you are hoping to link (in our case here, the admin-country variable in each dataset – “admin_country_CONFLICTfile” and “admin_country_POPfile”, respectively).
Copy and paste the admin-country observations from one dataset, and then ensure that each is matched to the correct corresponding admin-country in the other dataset(s). This is a manual task, where you should review to make sure that each admin-country name is correctly paired. Depending on the number of observations, this may take a little time. They may not be, nor need to be, perfectly matched spelling-wise, but need to refer to the same place. The key that we will create will allow us to match regardless of the differences in names. See Step 2 below.
You should generate a new column for each dataset you want to link (so here, 2 columns referring to our 2 datasets of interest [conflict and population data], in addition to the ID_variable column, are created). Ensure that admin-countries are not repeated – i.e., despite the fact that admin-countries are repeated in each dataset in line with your time (year) variable. Each panel indicator should show up only once in your ‘key’ in order to ensure Excel will match things across datasets correctly.
Lastly, you will add your new ID variable to all observations across the datasets you wish to link. See Step 3 below. Simply create a consecutive number in your ID_variable column. This is your “Key ID”.
You need to create a column in each of your contributing datasets called ID_variable. This can be done by inserting a new column in each dataset, and then using a VLOOKUP function in order to assign your Key IDs based on your common linking variable across all worksheets (this process will be explored in further detail below). For example, when assigning IDs to the conflict dataset file, we will use the admin_country_CONFLICTfile variable in our key file as the linking variable, as this is the variable that is identical across the conflict file and the key file. This will allow us to bridge between the Key ID and the Conflict file’s administrative ID.
To do so, we must first move our administrative-name column each time before using the VLOOKUP function. It must be the first (left-most) column in our key file in order to correctly specify our formula (reviewed below). This can be achieved with a simple ‘cut column’ followed by ‘insert cut cells’.
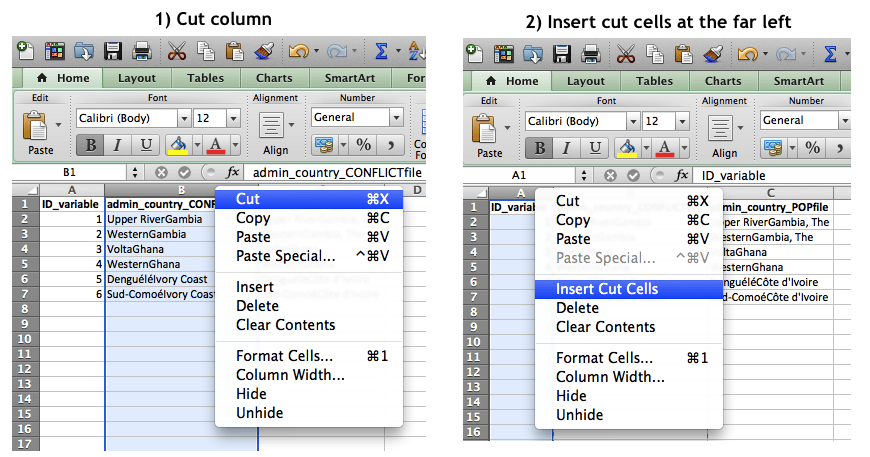
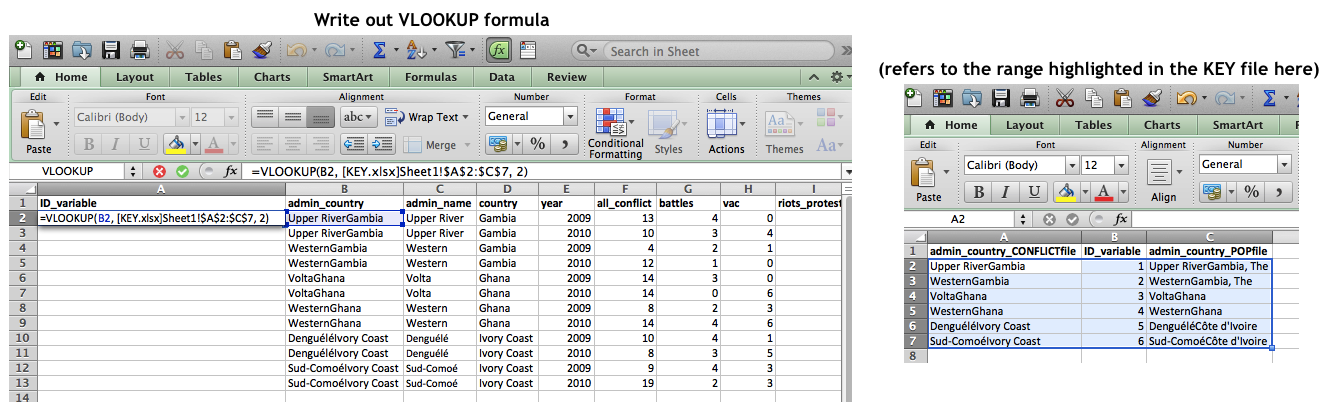
Once the key has been formatted correctly, we can assign IDs in our contributing datasets accordingly using the formula:
=VLOOKUP(B2, [KEY.xlsx]Sheet1!$A$2:$C$7, 2, false)
where B2 is the lookup value, in this case the admin-country identifying cell in your (conflict) dataset that you wish to match to the key; [KEY.xlsx]Sheet1!$A$2:$C$7 refers to your table array, in this case the key file and corresponding sheet, along with the fixed ranged in your key file highlighting all of your table values; 2 refers to your column index number, in this case the column number that should be out put (this is your ID_variable that you have created, which is the second column in your key file, hence “2”); and lastly, false refers to the outcome of your range lookup argument (by specifying that this argument is false, you tell Excel to find only an exact match to match upon in your key file). You should be using the VLOOKUP formula in your associated files (e.g., the Conflict or Population datasets in this example). You do not use VLOOKUP in your key file.
Once you’ve written out the correct formula once, you can drag and fill the rest of your column with the formula (given that you have fixed your key file range while leaving your lookup value to vary).
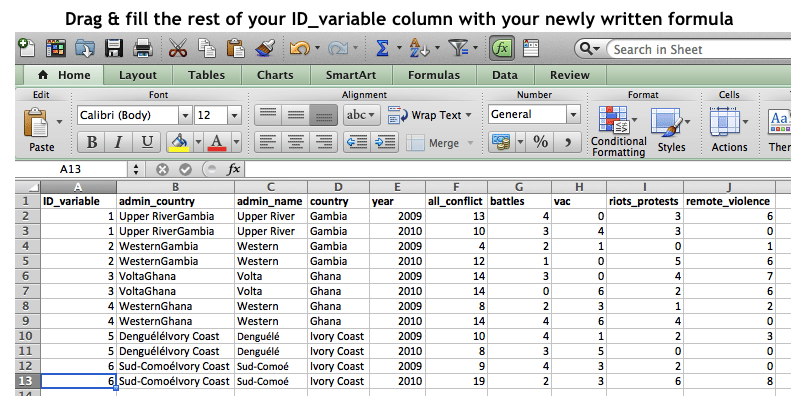
Again, make sure to copy and paste the newly generated entries as ‘values’ so that they will not be altered with the continued manipulation of the datasets!
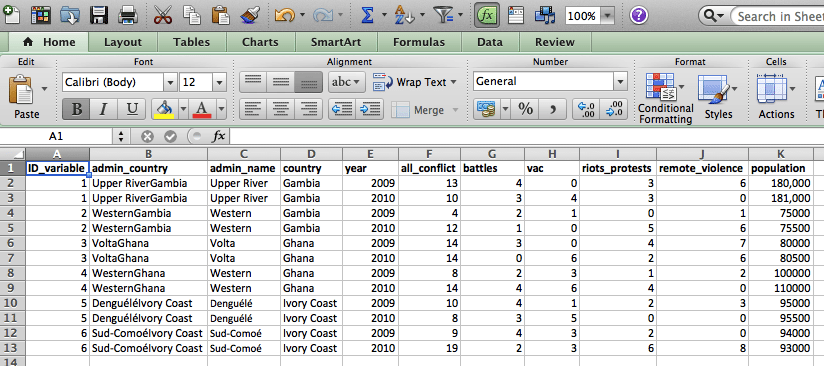
Then, repeat this same process for your other dataset(s) you wish to link (in our case, now that the ‘Conflict’ dataset is done, we will move on to the ‘Population’ dataset). Ensure that you again set the correct admin-country-identifying-variable as your leftmost column of your key file before beginning the VLOOKUP process.
Once you have done this for all of your contributing datasets, you have an ID-variable that you are able to use as your unique panel identifier across all datasets. This can then be used in merging time-panel data in programs such as Stata as your ID-variable will be a unique identifier that can be used in linking or merging. This will allow for the ultimate creation of a final dataset that provides you with all of the data that you are interested in across all time-panels.
Notes
[1] A data bank summary spreadsheet with other helpful datasets can be accessed here.
[2] The data/numbers used here are fake and are only listed here in order to help in painting a clear picture!



